
In the practice of pharmacy, precision dosing is an essential concept, especially in optimizing drug therapies for individual patients. One approach gaining traction in this pursuit is Model-Informed Precision Dosing (MIPD), often augmented by Bayesian methods. While these terms might sound daunting at first, they offer powerful tools for tailoring drug regimens to patients' specific characteristics. In this post, we'll provide an introduction into MIPD and Bayesian methods, demystify some of the associated jargon, and explore pharmacy-specific considerations.
What is Model-Informed Precision Dosing (MIPD)?
MIPD involves utilizing mathematical models to predict drug exposure and response in individual patients. These models are built on patient datasets with drug samples taken at multiple points throughout a course of therapy; models include pharmacokinetics (PK) and pharmacodynamics (PD) where covariates play a pivotal role in the equations. Covariates are critical as they are patient-specific factors, ranging from age and weight to genetic polymorphisms and concomitant medications, and can all significantly influence drug PK and/or PD. By including covariates into PK/PD models, clinicians can achieve a more nuanced understanding of patient variability, leading to personalized dosing strategies to better fit individual needs.
Additionally, because the models mathematically describe drug concentration as a function of time, they can incorporate samples collected at any time during treatment, allowing for flexibility in drug sampling timing. These concepts are different from former standards of care which considered the average population’s PK rather than incorporating patient-specific factors into equations, and required samples to be collected at very strict time windows following drug administrations.
In essence, the adoption of MIPD is the rejection of a “one size fits all” approach for dosing medications. This methodology therefore becomes a valuable tool to help clinicians achieve therapeutic efficacy while minimizing the risk of adverse effects in medications with narrow therapeutic indices. Two examples include utilizing MIPD for vancomycin management to decrease vancomycin-associated nephrotoxicity and busulfan management to avoid veno-occlusive disease.
How does Bayesian statistics fit into all of this?
Bayesian methods play a crucial role in MIPD because they help adjust and fine-tune the understanding of a patient's PK using observed data (e.g., measured drug levels or other surrogate biomarkers). In Bayesian statistics, we start with a model or “prior”, such as a population PK model, that describes what we expect to happen based on patient covariates, also referred to as a priori predictions. We then update our priors using new information, such as therapeutic drug monitoring samples, allowing us to adapt the model to better fit the patient and make personalized dosing predictions as well as patient-specific PK parameters like drug clearance (CL) and volume of distribution (Vd). This is where Bayesian predictions of PK/PD come into play, as they are influenced by both the population PK model and the patients’ drug samples to make accurate individualized predictions and are referred to as a posteriori predictions.
A key feature of MIPD with Bayesian methods is that they can be used to better forecast drug exposure for doses scheduled to be given in a treatment course by incorporating updated covariates and adapting the PK parameters. Alternative methods take the latest drug level and assume the patient will remain stable. Thus, if a patient’s renal function were to change, for example, then the pharmacist would need to get another level and check to see if they were still therapeutic or not. With MIPD, updated covariates (e.g., serum creatinine) are signals that the patient’s kinetics have changed and will result in updated calculations to show if the current regimen will still keep the patient therapeutic.
Demystifying MIPD/Bayesian
Navigating the intricacies of MIPD and Bayesian methods can often feel like deciphering a complex language, when in reality it’s not too complicated! You can think of MIPD and Bayesian forecasting for drug dosing almost as feedback loops that start with initial assumptions derived from population PK models. These models’ assumptions are then continuously refined with individual patient data on how the patients handle the drugs in their body to further optimize and personalize drug dosing.
First, let’s consider the inputs and outputs of MIPD by viewing the figure below where the inputs and outputs of MIPD are displayed:
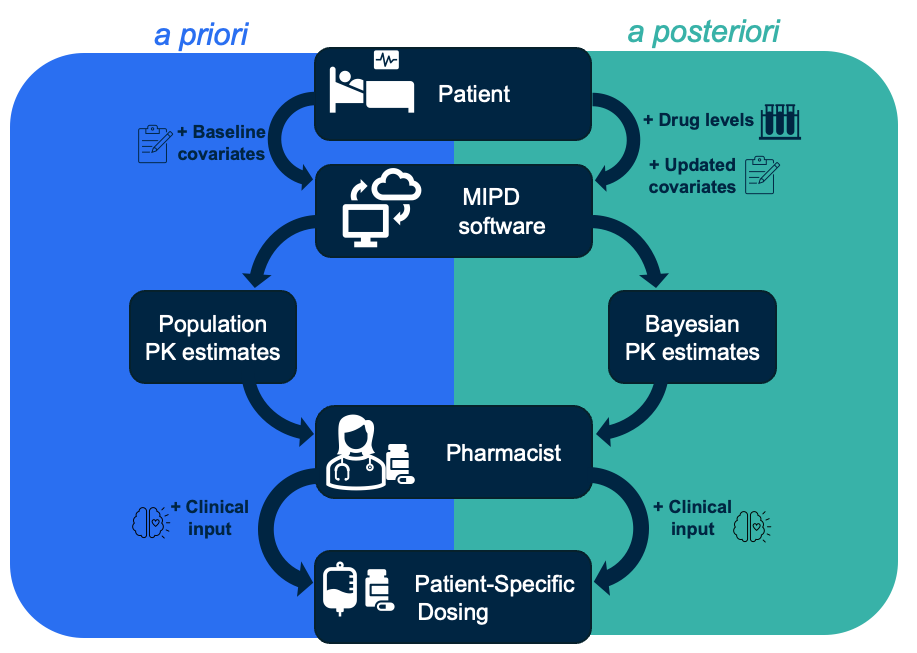
In the above figure, the left side is labeled as a priori and has a blue background. Following the arrows on this side, starting from the patient at the top, we see that first baseline covariates from the patient will be inputted into the MIPD software. Then population PK estimates will come from the MIPD software and will be available to the pharmacists who will then incorporate their clinical input to ultimately come up with patient-specific dosing recommendations.
The right side is labeled as a posteriori and has a teal background. Following the arrows on this side, starting from the patient at the top, we see that drug levels and updated covariates from the patient will be inputted into the MIPD software. Then the Bayesian-based PK estimates will be available to the pharmacists who will incorporate their clinical input to ultimately come up with the patient-specific dosing recommendations.
The key differences between a priori and a posteriori, are that in the a priori period incorporates baseline covariates to come up with population PK estimates; however, in the a posteriori period updated covariates are incorporated to reflect patients’ changes during their therapy as well as drug levels which then produce Bayesian-based PK estimates which are more individualized. Both periods of MIPD include the patient-specific information, and pharmacists’ inputs.
Pharmacy-specific considerations
The novelty of MIPD/Bayesian solutions can sometimes call for a reconsideration of conventional PK principles commonly introduced to most pharmacists. Dose individualization with MIPD provides a more sophisticated approach to understanding drug PK compared to the equations from models often taught in pharmacy school.
In teaching PK, many students are introduced to simplified models, such as the one-compartment model, which assumes that drugs distribute uniformly throughout the body and are eliminated at a constant rate (also known as first-order elimination kinetics). While this model is useful for conceptual understanding, it oversimplifies the complexities of drug metabolism and may not accurately represent real-world scenarios for many drugs.
MIPD modeling, on the other hand, embraces the complexities of drug metabolism by incorporating more detailed physiological and PK parameters. These include the following:
- MIPD considers multi-compartment distribution, where drugs may distribute differently between central and peripheral compartments within the body.
- MIPD acknowledges non-linear elimination kinetics, where the rate of drug elimination is not constant but instead changes as drug concentrations increase or decrease.
- MIPD can take into consideration other impactful patient characteristics such as pharmacogenomics and drug-drug interactions.
Due to the additional complexities, pharmacists may experience a learning curve when it comes to understanding these PK differences represented in MIPD. However, MIPD modeling is embedded in software programs that have clinical decision support (CDS) and are made to be user-friendly. If pharmacists understand how an MIPD program works, they can then appreciate the advantages it has on their day-to-day workflows.
Given that Bayesian MIPD eliminates complicated math at the bedside, enables much more convenient laboratory sampling times, and can transfer data automatically from the EHR, interdisciplinary teams should experience improved workflow efficiencies. By incorporating these more nuanced aspects of drug PK, MIPD modeling enables healthcare professionals to better predict drug concentrations in individual patients based on their unique physiological characteristics, allowing for more precise dosing recommendations tailored to each patient's needs.
Conclusion
MIPD and Bayesian dosing methods offer pharmacy practitioners powerful tools for personalized dosing, integrating patient-specific data and prior knowledge to optimize drug therapies.
Want to know more about MIPD? Talk with an expert by clicking the link below!
