
Introduction
The current gold standard approach in model-informed precision dosing is based on statistical models for predicting drug exposure, to be precise: population pharmacokinetic (PK) models paired with Bayesian forecasting. All currently available precision dosing software (including the InsightRX Nova platform) uses this approach in some shape or form, and these applications are used by thousands of hospitals across the US and abroad every day.
Artificial intelligence (AI) and machine learning (ML) are currently disrupting many fields. So the obvious question to ask is whether this will happen for the field of precision dosing as well? Should we see this as an inescapable development? Will precision dosing become a fully ML-based approach? Can we ditch approaches based on PK models? Or are there inherent qualities in PK models that will stay useful?
This post is primarily written for clinical pharmacists, pharmacometricians, and hospital decision-makers evaluating precision dosing technologies. If you're familiar with population PK models and Bayesian forecasting, you'll find the technical comparisons straightforward. If you're newer to the field, I've tried to keep the discussion accessible while still being substantive.
At InsightRX, we have been exploring and adopting ML and AI in our own workflows and software products for a long time, such as in model selection algorithms, and neutropenia prediction algorithms. While we are forward-looking, we focus first and foremost on the clinical practicality of the tools we develop and how they fit into clinical workflows. Here, we try to cut through the hype to understand the current and potential role for AI and ML in precision dosing. Let's dive in!
Machine learning
I'd like to start by defining machine learning (ML) as I will use the term in this post. ML encompasses a broad set of techniques that have been refined since the 1970s and adopted widely across research and business in the last 10-15 years. These methods excel at forecasting specific outcomes—like stock prices, weather patterns, or in our case, drug exposure—by learning patterns from large datasets.
You may be wondering about generative AI and large language models (LLMs), which have dominated recent headlines. While these technologies have potential applications in clinical pharmacy (documentation, literature review, patient education), they're fundamentally different from the predictive ML models we'll discuss here. LLMs predict the next token in a sequence of text, while the ML approaches relevant to precision dosing predict specific numerical or categorical outcomes. I'll focus exclusively on predictive ML in this post.
Refresh: how do population PK models work?
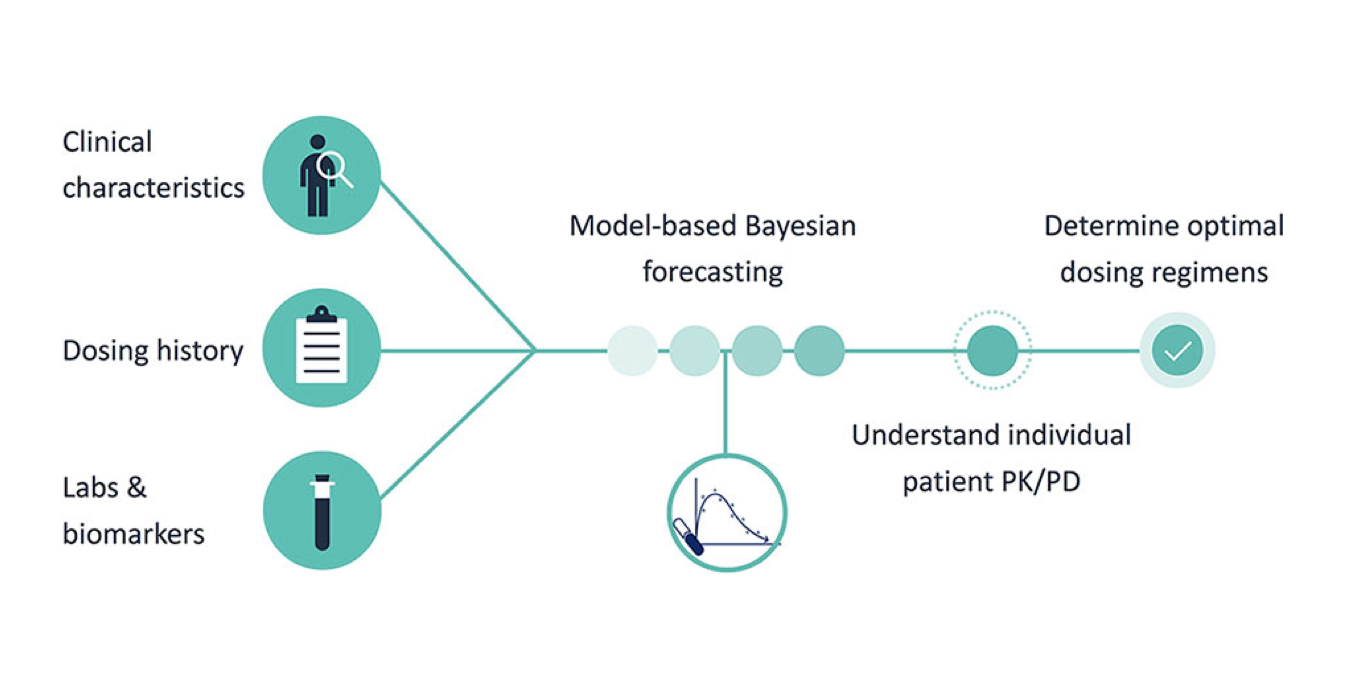
Before we dive deeper into ML for precision dosing, I’d like to recap how population PK models work. These models describe the concentration-time curve of a drug over time, as well as the variability within a population (hence the term “population”). Some of that variability can be explained by a limited set of predictors (usually 2-6, like body weight, creatinine clearance, albumin, etc) that influence the key model parameters, like drug clearance and volume of distribution.
Models also capture unexplained variability. Over time, through the sampling of drug concentrations (therapeutic drug monitoring, TDM), this unexplained variability for a given patient can be reduced using Bayesian updating of PK parameters. Through simulations from the model, we can figure out an optimal dosing regimen for the individual patient. The process is shown schematically in the figure below (Frymoyer 2020):

Figure 1: model-informed precision dosing, based on population PK models
How can ML models be used in precision dosing?
In this blog post, with “precision dosing” I mean determining the dosing regimen for drugs for an individual patient. ML can also help with other drug-related clinical questions such as selecting the right antibiotic drug, but I won’t be talking about that here. Here, I’m distinguishing four separate ML approaches that can be leveraged in precision dosing:
- Forecasting: as a replacement for population PK
- Hybrid approaches
- Exposure estimation
- Reinforcement learning
Forecasting: as a replacement for population PK
Perhaps the most obvious application of ML is as a replacement of population PK models for the forecasting of concentration over time. Many publications have explored this in some shape or form (some recent examples for vancomycin are e.g. Park 2025, and Ghanbari 2025, but there are dozens more examples).
The specialty of ML models is their ability to extract highly accurate predictive models from a large number of potential predictors, in contrast to the limited sets of carefully chosen predictors used by population PK models. Especially if the clinical data is higher-dimensional (e.g. 20+ or more different patient characteristics or laboratory measurements), ML models are usually more predictive than the more rigid “non-linear mixed-effects” statistical models that underlie population PK models. However, this advantage does come with caveats and potential drawbacks.
One drawback, for example, is that all selected predictors during model training also need to be available at the time of inference at the point-of-care, and not only when the model is trained. This introduces a potential limitation because it hinders transferability to other hospitals where not all biomarkers may be measured, or are measured using different assays. Of course this same limitation is present for PK models, but PK models usually take only a handful of covariates such as weight, age, and renal function, so in practice this is less of an issue.
Another important drawback is that ML models are single-purpose (i.e. they are trained to predict a single measure, such as “the trough concentration 48 hours from now”), while PK models incorporate an actual semi-mechanistic model of drug disposition and can simulate any drug regimen in terms of future concentrations, area under the curve (AUC), or other derived measures like “time above MIC”.
Finally, individual parameters of PK models are interpretable: for example they provide an estimate of the actual drug clearance, half-life, and drug distribution into tissues, which can be valuable information for determining dose intervals, sampling times, and patient discharge. The user is also able to interpret if the individual estimates are far off from the standard patient. For ML models such a mechanistic interpretation is absent, as the model is just a black-box. [1] Table 1 summarizes these key differences between population PK and ML models.
One application where this ML approach could bring the largest advantages is for patients in the intensive care (ICU). Patients in the ICU commonly show more complex and variable physiology. Traditional MIPD in these patients has so far met with limited success—especially results for beta-lactam antibiotics results have been poor so far. The ICU is typically where much more patient data is recorded compared to general wards, and therefore ML may be able to use these higher-dimensional datasets to its advantage.
| Population PK models | ML models | |
| Patient data needed for training | 10s-100s | Several 100s or more |
| Parameters | Interpretable | Not interpretable |
| Extrapolation beyond training data | To some degree, due to mechanistic aspect | Should be avoided, performance unclear |
| Predicts | Any direct or derived PK parameter or exposure measure | Single measure, usually Cmin |
| Ability to handle many (e.g. > 20) predictors | Poor | Good |
| External performance | Reasonable | Poor |
Table 1: Comparison table ML vs PopulationPK, typical characteristics
In summary, for it to be worthwhile to develop and implement an ML model in clinical decision support (CDS) tools, their performance should be meaningfully better than that of a PK model. Otherwise, the complications and drawbacks of ML models listed above will not outweigh their benefit. And even then, care must be taken that the developed model can actually be implemented and can be adopted across health systems.
As discussed in Markowetz 2024 “Successful models use data that are available in routine practice”. For this reason, when developing ML models intended to be used across health systems, it may be wise to intentionally limit the set of predictors to those that are also likely to be available across institutions. This however may make ML models lose their edge in performance over the PK models that we were seeking in the first place…
Hybrid approaches
To mitigate some of the drawbacks described above, several research groups have sought to marry the PK and ML approaches and aim for the best of both worlds. Such hybrid PK-ML models come in various shapes and forms: For example, hybrid models (or systems) can be leveraged to help select the best PK model for a patient, given their characteristics, or to tweak the predictions of existing PK models. The reverse can also be done, where population PK models can be leveraged to improve ML models. The addition of knowledge inherent in PK models can thus help constrain ML models to more realistic output.
Another hybrid approach that operates at an even deeper level is when neural networks are added into the differential equations that make up population PK models, as presented in Valderrama 2023, for example. This could lead to more flexible PK models than available through standard PK modeling, and allow the inclusion of more complex covariate relationships.
Although to my knowledge no hybrid approach is currently being used routinely in the clinic, the use of hybrid models is one of the clearest applications where ML can be used in CDS tools, and may become available in the next few years. An obvious drawback is still that, to develop and implement hybrid models, knowledge of both population PK and ML is needed as well as different software tools, and the models will inherently be more complex to train and implement than either single approach. But if these hurdles can be overcome, they may be able to remove some of the limitations of the single approaches mentioned above.[2]
Exposure estimation
So far in this post we’ve considered PK or ML models as predicting future concentration time profiles, and determining dose changes based on those predictions. But if we are only interested in estimating the current area-under-the-concentration-curve (AUC) from a set of concentration samples from a patient, we can also leverage ML for that.
One of the earliest instances of this approach came from the Woillard group in France. This group has shown in numerous papers how ML can be used to estimate AUC from limited sampling, for example for tacrolimus, mycophenolate, and daptomycin. They showed how this approach is more flexible than classical limited-sampling approaches and more performant.
While some of the drawbacks of ML approaches mentioned above still apply, the performance of this method to estimate drug exposure (AUC) has been shown to be equal to or better than Bayesian estimates of past AUC. It must be noted, however, that this approach just focuses on fitting retrospective data, and is therefore more similar to a non-compartmental analysis (NCA) than Bayesian dosing. In contrast to Bayesian forecasting, it does not attempt to optimize future forecasting performance (the importance of which I highlighted in a previous blog post).
So even though this method performs well for estimating AUC, it is still unclear whether the approach is actually better able to optimize drug regimens and drug exposure compared to population PK-based approaches. The approach is already used routinely in the therapeutic drug monitoring service at the University Hospital of Limoges.
Reinforcement learning
A very different approach is offered by reinforcement learning (RL): this is a technique that can learn optimal strategies for complex decision-making problems, particularly when many actions are available and there's no obviously optimal approach. RL achieved fame through victories in games like chess and go, where it learned superhuman strategies without being explicitly programmed with game theory.
The appeal of RL for precision dosing is that it could potentially discover effective dosing strategies directly from clinical data, even without requiring a mechanistic understanding of drug pharmacokinetics or pharmacodynamics. Several research groups have explored this potential, with promising results in simulation studies (e.g. in oncology, and anesthesiology). However, RL faces significant practical barriers in precision dosing.
For one, RL models typically require very large datasets—containing thousands of patients with recorded dosing decisions, contexts (patient characteristics, biomarkers), and outcomes. This scale exceeds what most research institutions have available for any single drug. Also, even experienced practitioners acknowledge that RL models can be challenging to train and tune correctly, requiring careful attention to reward functions, exploration strategies, and hyperparameters.
To overcome data limitations, researchers have proposed training RL models on data simulated from population PK-PD models. While technically feasible, this creates a circular dependency: if we have PK-PD models accurate enough to generate training data, why add the complexity of RL rather than using the models directly for dose optimization? The RL approach would need to demonstrably outperform direct model-based optimization to justify its additional complexity.
RL could be most useful in scenarios where we have abundant clinical data but limited mechanistic understanding, for example:
- New drugs lacking validated PK-PD models
- Complex dosing problems, e.g. multi-drug dosing decisions with potential interactions
- Situations where the relationship between exposure and outcome is unclear
- Large integrated health systems with comprehensive EHR data across thousands of patients
The challenge is that these conditions rarely occur together. Poor mechanistic understanding typically correlates with limited clinical data, not abundant data.
As precision dosing software becomes more deeply integrated with EHR systems across large health networks, RL could become more viable for emerging therapies. In such scenarios, RL might help identify effective dosing patterns during a drug's early clinical use, buying time until more rigorous PK-PD models can be developed and validated.
For now, RL remains a promising but immature approach for routine precision dosing. The field would benefit from head-to-head comparisons of RL versus PK-based approaches in realistic clinical scenarios, as simulation studies alone provided limited insight into real world performance.
Research and Evidence
We’ve already touched on a few challenges for applying ML in precision dosing. Another important reason why the precision dosing field has not adopted AI or ML in clinical practice is that these models are often not compared with gold standard methodology.
One of the most common fallacies[3] in ML publications is the evaluation of its performance: ML model performance is commonly evaluated on a “test” dataset, but too often this “test” dataset is very similar to the training data, usually from the same hospital that was used to “train” the data. Compounding this issue is that in many cases, the “gold standard” population PK model to which the ML model is evaluated against is not selected with care (I’ve written about the importance of model selection previously), and thus renders the comparison even more skewed and unrealistic.
One way to mitigate this problem would be to also retrain or redevelop a population PK model on the test data. But the only way to perform a proper comparison of real-world performance of ML would be to test the models against true out-of-sample scenarios (multi-site, preferentially). This was done in Verhaeghe 2022, which showed reasonable performance of ML models in some dosing scenarios, but not consistently outperforming PK models.
Beyond validation design, there's also a publication bias to consider: studies showing ML models outperforming PK models are more likely to be published than those showing equivalent or inferior performance. This creates an artificially optimistic picture in the literature.
So what should rigorous evaluation look like? Ideally, one would like:
- External validation: Test on data from different hospitals, ideally multiple sites
- Prospective comparison: Compare ML and PK recommendations on the same patients
- External validation: Test on data from different hospitals, ideally multiple sites
- Fair baseline: Use well-selected, contemporary PK models and dosing algorithms as comparators, not outdated literature models
- Practical metrics: Evaluate not just prediction accuracy but also target attainment and clinician usability, and ideally patient outcomes and toxicity.
Until we see more studies meeting (at least some) of these standards, claims about ML superiority should be viewed cautiously.
Regulatory
Another critical consideration for ML in precision dosing is the regulatory pathway. The FDA's guidance document on CDS software provides clear criteria: if users cannot "independently review the basis for the recommendations," the software could be classified as a medical device requiring FDA clearance or approval.
In contrast, population PK-based software can typically show their work: "We recommend this dose because the patient's estimated clearance is X, and simulation shows this dose achieves target exposure." ML models face a steeper challenge due to their limited mechanistic interpretability.
Modern interpretability techniques[4] can provide some insight into which patient features drove a prediction. However, it is unclear whether these techniques satisfy FDA's "independent review" criterion as Non-Device software. Having to obtain FDA clearance adds considerable burden and cost to development and deployment of CDS. This means that ML-based CDS tools will need to show an even higher ROI than current gold standard softwares to be able to reach the clinic.
Conclusion
After this critical examination, where does ML stand in precision dosing?
The pragmatic view: ML is neither a silver bullet nor irrelevant. Its value depends entirely on the specific application and clinical context. For straightforward dosing scenarios with well-characterized drugs and established PK models, ML adds complexity without clear benefit. For complex scenarios with high-dimensional patient data or poorly characterized drugs, ML may offer genuine advantages—but only if properly validated and made practically implementable.
Near-term opportunities: The most promising applications are hybrid approaches that combine PK mechanistic understanding with ML flexibility. These could include ML-assisted model selection, ML-enhanced covariate modeling, or ML-based refinement of PK predictions. These hybrid methods could reach clinical practice relatively quickly, as they preserve interpretability while potentially improving accuracy.
Medium-term potential: As precision dosing software becomes more deeply integrated with comprehensive EHR data across health systems, purely ML-based approaches may become viable for select drugs and populations. Reinforcement learning might find niches in personalized multi-drug regimens or emerging therapies. The field needs honest, rigorous comparative studies with proper external validation. And we need transparent discussion of implementation barriers, not just technical performance metrics.
At InsightRX, we remain committed to using the right tool for each job. Sometimes that's a classical PK model. Sometimes it's a hybrid approach incorporating ML. Sometimes it might be pure ML. The goal isn't to chase new technology, but to deliver measurably better patient outcomes with solutions that clinicians can trust and use effectively. New methods must earn their place by demonstrating clear, reproducible benefits that outweigh their costs and complexities. ML will have its place in precision dosing, but that place will be earned through rigorous evidence, not hype.
So if you're evaluating ML-based precision dosing tools, ask tough questions about validation, interpretability, and practical implementation. And if you're developing such tools, hold yourself to the highest standards of evidence. Patients deserve nothing less.
Evaluating ML-Based Precision Dosing Tools: Key Questions
If you're considering implementing ML-based dosing software, ask vendors about:
Validation
- Was the model validated on truly external data (different hospitals)?
- What was the performance in patient populations similar to yours?
- Have the validation results been published in peer-reviewed journals?
Practical feasibility
- Are all required predictor variables available in your EHR?
- How does the software handle missing data?
- What happens when laboratory assays differ from those used in training?
Interpretability
- Can the software explain why it made a specific recommendation?
- What regulatory status does the software have (FDA cleared, 510(k) exempt, etc.)?
Maintenance
- How often does the model need retraining?
- What monitoring is in place to detect model degradation?
- Who is responsible for ongoing validation?
Comparison
- How does performance compare to established PK-based approaches for the same drugs?
- Were comparisons made against current best-practice PK models?
Footnotes
- Various approaches exist for make ML models more interpretable, such efforts are called “interpretable AI/ML” (how a prediction has been made) or “explainable AI/ML” (why a prediction has been made), although the terms are also used interchangeably.
- For an overview of hybrid modeling approaches see (e.g) Stankevičiūtė 2023.
- Another very common pitfall in precision dosing ML research is “data leakage”, in which forecasts are made based (partially) on future predictors that are not available at the time of decision-making.
- While techniques like SHAP values and LIME can provide some insight into model predictions, they don't offer the same mechanistic understanding as PK parameters.